Regression accuracy: Excel’s regression vs. the SSDM algorithm
A recent post on the MSDN Forums raised an interesting issue: Excel Data Analysis’s Linear Regression and SSDM were returning different results. Specifically, the SSDM results were much worse.
The issue turned out to be a data modeling issue (columns were not mapped properly). However, during the investigation I had to compare Excel’s linear regression with the SSDM regression algorithm(s). Thought this might be interesting, so here is one way to compare the results from the two implementations.
I started with some simple (X,Y) data (available for download as a CSV file). First step - run Excel’s Data Analysis regression tool. The results are displayed typically in a separate spreadsheet, and the interesting part is the Coefficients sections:

Therefore, the Excel regression formula is
Y = 2.37486095661847*X -0.310344827586214
Next thing — apply Excel’s regression coefficients to the existing data. I did this by adding a column in my data spreadsheet and populating it with a formula:

Next thing, I created a Microsoft Linear Regression mining model on the same data. There is a variety of ways to do this, such as exporting data to a table, connecting directly to the Excel spreadsheet or, the simplest way, by using the Excel add-ins.
To get the model’s predictions in Excel, I used one of the functions exposed by the Excel add-ins, DMPREDICT. If you do not have the add-ins you can always execute a prediction query in SQL Server Management Studio or BI Dev Studio.
However, with the add-ins’s function, getting the prediction results is really easy:
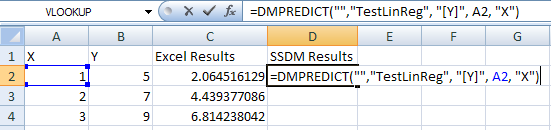
The function syntax:
DMPREDICT(”", “TestLinReg”, “[Y]”, A2, “X”)
- the first parameter (empty string) is the Analysis Services connection to be used. An empty string refers the current connection.
- the second parameter, “TestLinReg”, is the name of the mining model that will predict
- the third parameter, “[Y]”, is the requested predicted entity (predictable column, in this case, but could also be any prediction function)
- the last two parameters define the prediction input: the value in the A2 cell should be mapped as “X”.
The DMPREDICT call resolves to a DMX query like below:
SELECT [Y] FROM TestLinReg NATURAL PREDICTION JOIN
(SELECT [A2] AS X ) AS T
where A2 is replaced with the actual value. With Excel’s auto-fill feature, getting all the predictions is really easy.
Now, with both result sets at hand, we can compare them. I created two absolute error columns, one for the Excel’s regression results and the other for SSDM’s prediction results.

The column for SSDM absolute error has a slightly different formula: =ABS(D2-B2) (to use the column populated with DMPREDICT)
The last steps: use the absolute error columns to compute the Mean Absolute Error and Root Mean Squared Error for both result sets:
Again, Excel’s calculation engine does most of the work:


The final results suggest that there is no significant difference between the results returned by the two regression algorithms for this data set:

[…] know from sqlserverdatamining.com and the DM Forums has started his own data mining blog - with a first entry to answer many of the questions around "Excel does this and DM does that". In this […]
Great new look for the site.