Companion for MS Analysis Services
Today I discovered a very nice Analysis Services client tool. Produced by SQLMinds, the tool seems a great addition to Analysis Services. It provides many components, among them a performance tuning service, an OLAP cube browser for the web and a very nice web front end for data mining, the DM Companion tool which can be launched at http://x32.sqlminds.com/dmcompanion.
So, here are a few really nice things about the DM Companion tool (BTW, a fully working demo is running at the aforementioned URL).
The tool works to some extent like a Data Mining -specific SQL Server Management Studio for the web. Therefore, it allows you connect to the server of your choice (through the Analysis Services HTTP pump). The demo seems to allow anonymous connections (pretty safe as all the interactions offered by the tool are read-only). Next you get to chose your AS catalog and the mining model you want to use.
For each model you have the option to browse the content or execute predictions.
The prediction feature provides a nice interface for defining singleton predictions, as you can see below:
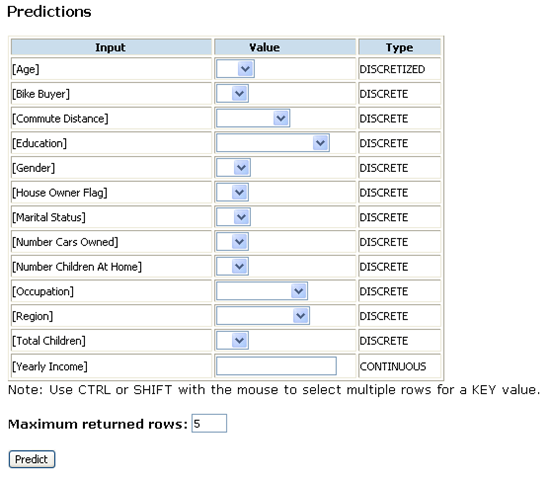
The interface supports specifying multiple nested table keys as input, so the tool can perform associative predictions as well. It reminds me of the XMLA Thin Miner sample running on SQLServerDatamining,com, however, it looks much better and is nicely integrated with the rest of the application. While prediction functions do not seem to be directly supported, the application is able to predict a cluster for clustering models.
The model browsing features are really nice. Analysis Services includes a set of sample web viewers for Naive Bayes, Trees and Clustering. This application provides some seriously better looking viewers for these algorithms, and extends the suite at least for Neural Networks (a really nice viewer), Sequence Clustering and Association Rules. The DM Companion viewers offer all the features in the sample viewers, with a nicer implementation which uses AJAX and has better graphics, plus a solid set of new features, the most spectacular being the interactive dependency net browser and the pie chart visualization for decision trees, which you can see below.
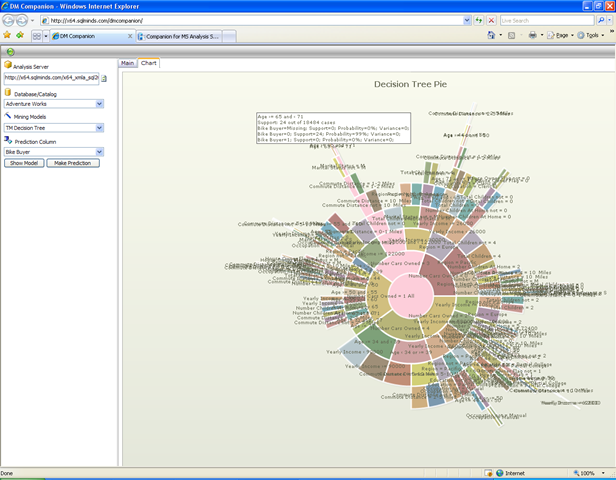
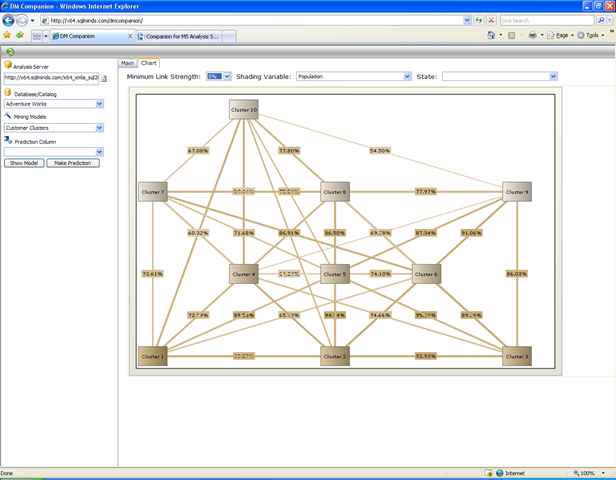
Overall, DM Companion looks like a really nice tool for sharing your data mining implementation on the web


